
Introduction
Polar Packet recently engaged with a local leading news agency to provide services in building cutting edge data analytics capabilities to spearhead its data analytics adoption. As the local news agency gains more followers, it needed a way to tag articles at scale with minimum user intervention.
Problem statement
When people visited their news site, they don’t expect to just read about their favourite celebrity or gossips but rather others topics such as animal conservation or the recent flood. The local news agency covers a lot more than gossip.
In order to understand what kind of content would resonate with their audiences, these “tags” that are found in each articles are useful in helping them to understand more about their audience. By reducing the manual labour work that are involved in tagging each article, writer can spend more time on writing more quality contents and curate content for their reader at a deeper level.
With their increased focus on increasing customer engagement and retention, Polar Packet comes into the picture to help them understand their audience, create models that can deliver more personalised and curated news experiences. As part of this initiative, the Polar Packet team sought out to build an automated topic model to help annotate and organise their content.
Solution
A topic modelling model build using TFID vectorizer and LDA to abstract topics from the corpora. LDA is a generative probabilistic model for identifying abstract topics from discrete dataset such as text corpora. Once automated, model would classify an article into relevant topics groups that are suggested by the LDA on a daily basis.

Félix Revert on An Overview of Topics Extraction in Python with Latent Dirichlet Allocation
Let’s Breakdown What it Means
Topic modeling is an unsupervised machine learning technique that aims to scan a set of documents and extract and group the relevant words and phrases. These groups are named clusters, and each cluster represents a topic of the underlying topics that construct the whole data set. Topic modeling is a Natural Language Processing (NLP) problem.
TFID converts documents to a matrix of TF-IDF features.
We then used Latent Dirichlet Allocation (LDA) as the topic extractor. This approach assumes that similar topics almost consist of similar words, and documents cover different and several topics. LDA assumes that the distribution of topics over documents, and distribution of words over topics, are Dirichlet distributions
Example Showcase
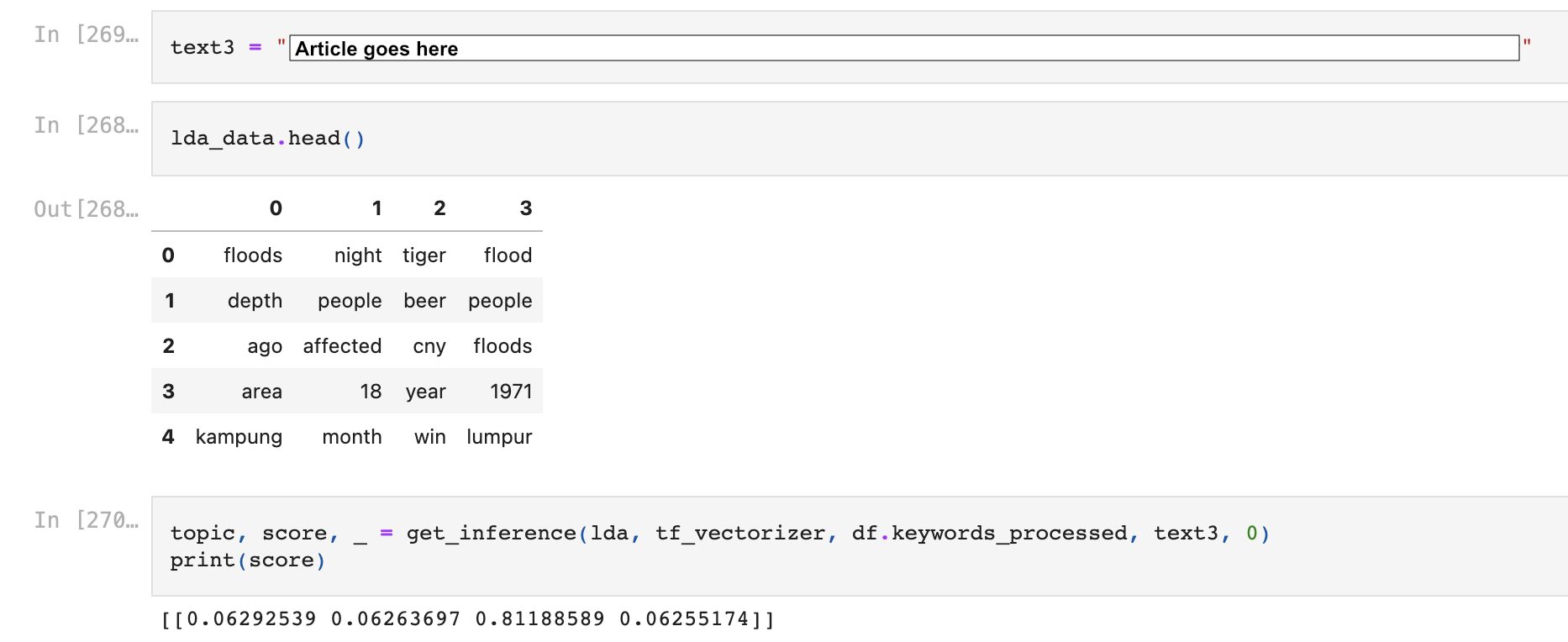
By training on a few Chinese New Year and flood related articles, our model came up with 4 topic groups. Then, given a string of text from a random news article on CNY, our model predicted with 81% probability that the text belongs to group 2 (Tiger, beer, cny…). With careful observation, we can safely say that the text indeed should be classify into CNY or Chinese New Year related news article.
Application to workflow
While news agencies are able to manually tag articles themselves, a machine learning approach to it would bring in more technical opportunities for them.
A good example for this, while the said agency would be able to manually tag “cny”, “Chinese New Year”, etc. They would not be able to apply article recommendations automatically as there is no association on “cny” and “Chinese New Year” as there is isn’t a dynamic semantic word processing behind it and the article poster would need to eyeball through all its news articles to re-link them.
The model trained would already suggest that the article has a 81% probability that the article is Chinese New Year related, irrelevant to the term they used.
Application to reporting
The model would then serve as a baseline model for all articles written, its trending tags, and allow deep dives into a level of detail of articles, opening doors for advanced analytics and enhanced Google Analytics (GA) application purposes.
ie, Applying tagging to a GA will allow the agency to build its reporting standards to understand overall performance based on tags and not just a page path level or a user aggregated level.
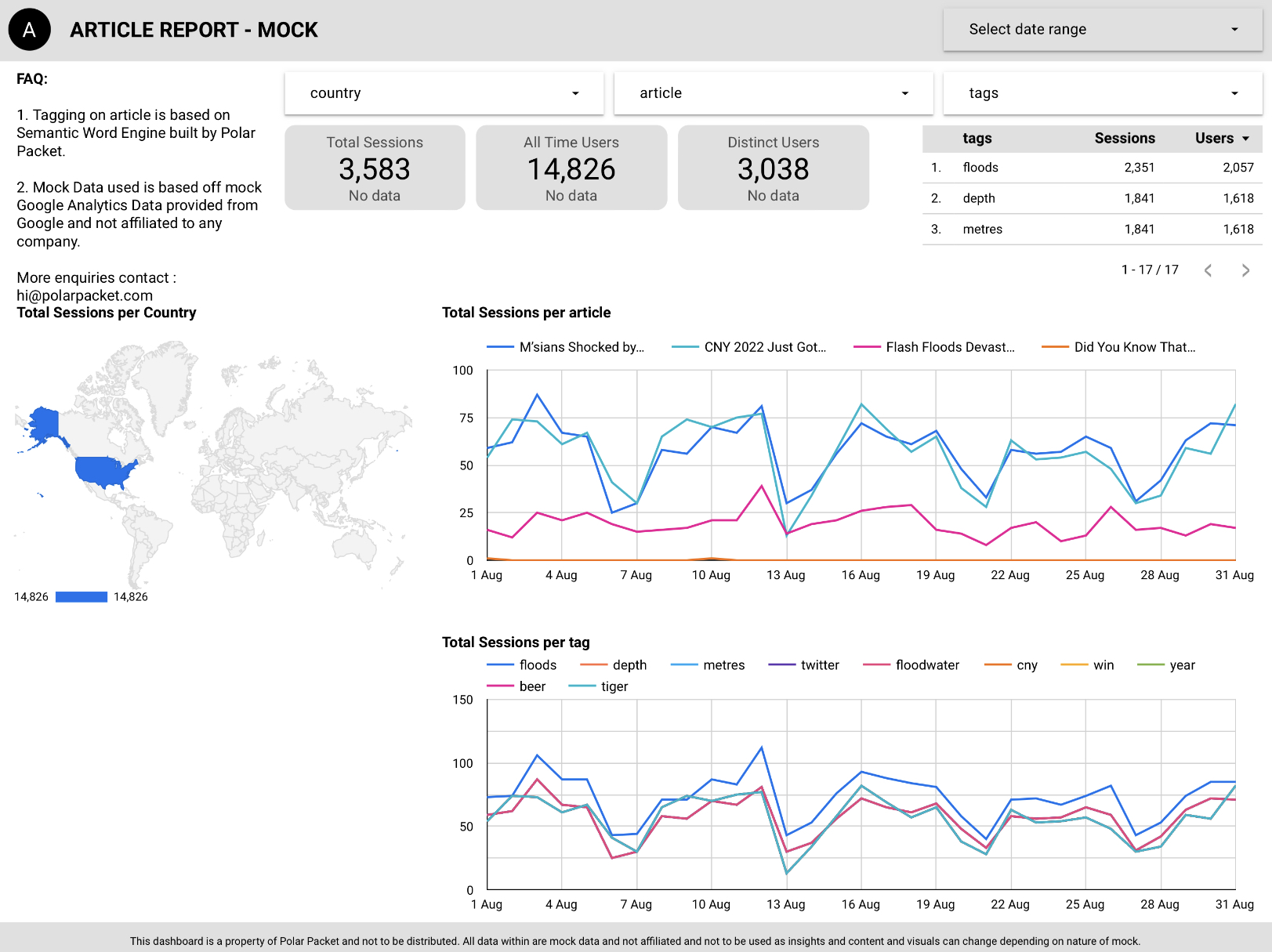
The model here is only trained with a month worth of mock GA data and on 5 articles scrapped from the web that allowed the corporation to drive data backed article recommendations based on trends and viewership on the article tags.
Application to Data Science
The model itself can also be used in a wide list of applications on data science, such as article recommendations, user personalisation, market attribution and so forth.
A backend web dev is then brought on to deploy a container below articles that would suggest users other articles similar to the one being written.
User personalisation models can also be deplored by understanding what articles to a person read and what seasons do they read such articles.
A good example of this is during pre-covid, users who are family based, and travel during the school breaks are suggested articles pertaining flights, allowing the agency to partner with airlines to provide collaborated suggested articles.
Market attributions is a means of targeting users based on the channel sources they use and having clearer picture on the ad spends required for the agency to push social media and BTL initiatives.
Need more information or engage with us?
Contact us at hello@polarpacket.com