· documentation · 5 min read
Data Lake, Data Warehouse, and Data Lakehouse: A Technical Comparison of Modern Data Solutions
In today’s evolving data landscape, understanding the key differences between data lakes, data warehouses, and the newer data lakehouse model is essential for effective data management. Compare their architectures, performance, and use cases, and understand how cloud platforms like GCP, AWS, Azure, Databricks, and Snowflake implement these solutions.

In today’s data-driven world, businesses rely heavily on effective storage solutions to manage large volumes of data. Three major data storage architectures—data lakes, data warehouses, and data lakehouses—have become popular in modern data management. This article explores their evolution, provides a comparison of their architectures, and highlights key use cases with insights from GCP, AWS, Azure, Databricks, and Snowflake.
A Quick History
Before delving into each concept, understanding their origins provides useful context:
- Data Warehouses (1980s): The data warehouse emerged in the 1980s to handle structured data, offering optimized storage for structured datasets, usually from operational systems. This system provided fast querying for business analytics and reporting.
- Data Lakes (2010s): As unstructured and semi-structured data increased, data lakes were introduced in the 2010s. Unlike data warehouses, they could store all types of data (structured, semi-structured, and unstructured) without a predefined schema, making them ideal for big data processing.
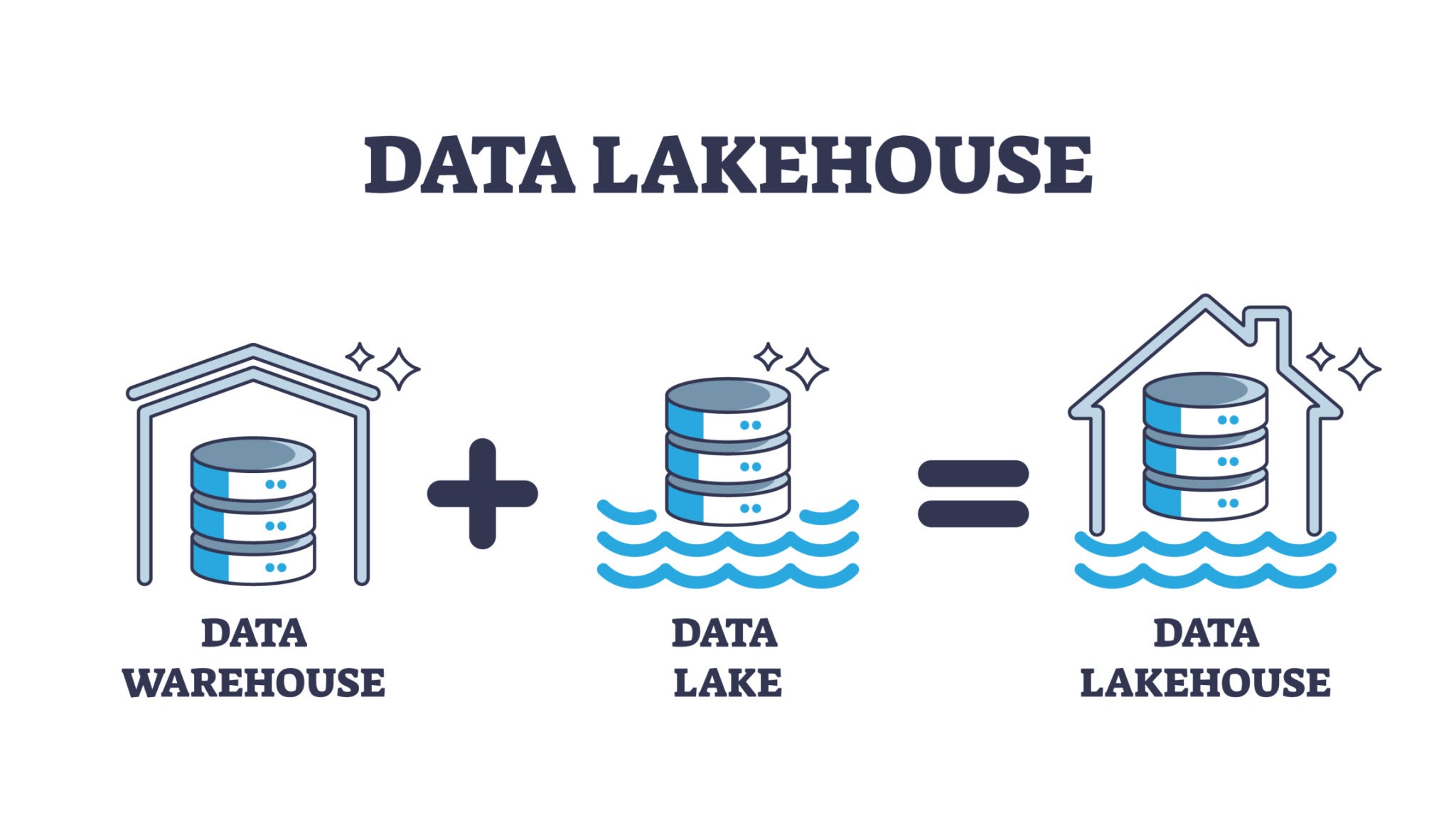
- Data Lakehouse (Late 2010s): More recently, the data lakehouse concept emerged, combining the benefits of both data lakes and data warehouses. It supports both high-performance querying on structured data and flexibility in handling unstructured data, all in one system.
What Are They Meant For?
Each data solution is designed for specific purposes:
- Data Warehouse: Primarily used for structured, relational data. It’s ideal for business intelligence, reporting, and historical analysis where high performance and reliability in querying are required. Data is carefully cleaned, structured, and optimized for analytical queries.
- Data Lake: This is a massive repository designed to store data in its raw form—structured, semi-structured, and unstructured data alike. Data lakes are often used in machine learning (ML), AI, and big data analytics due to their ability to handle diverse data types at scale.
- Data Lakehouse: As a hybrid solution, the data lakehouse is meant to combine the strengths of data lakes and warehouses. It allows for efficient querying on structured data like a warehouse while supporting raw data ingestion like a lake, making it perfect for advanced analytics, AI, and real-time data applications.
Why Are They Different?
The three architectures differ fundamentally in terms of structure, performance, and the types of data they are optimized for:
1. Storage Structure:
- Data Warehouse: Uses a predefined schema (schema-on-write) where data must be cleaned and structured before storage. This makes querying faster but limits flexibility.
- Data Lake: No schema is enforced when data is stored (schema-on-read), offering flexibility but at the cost of slower performance and data management challenges.
- Data Lakehouse: Offers schema-on-read flexibility but incorporates aspects of schema-on-write for certain data types, combining flexibility with performance optimization.
2. Performance:
- Data Warehouse: Optimized for fast, complex queries on structured data. Data is pre-processed and indexed to speed up performance.
- Data Lake: Not optimized for querying, as it stores raw data. Query performance is typically slower, especially for structured data.
- Data Lakehouse: By using indexing and data organization techniques (e.g., Delta Lake, Iceberg), data lakehouses improve query performance while maintaining data flexibility.
3. Data Types:
- Data Warehouse: Handles structured, relational data best.
- Data Lake: Ideal for a variety of data types, including unstructured (e.g., video, images), semi-structured (e.g., JSON, XML), and structured data.
- Data Lakehouse: Manages both structured and unstructured data efficiently, integrating features from both prior architectures.
How Can People Use Them?
The use cases for each solution depend on a company’s data needs:
- Data Warehouse: Best suited for organizations where structured data dominates and quick, reliable analytics are a top priority. Use cases include financial reporting, customer analytics, and operational analytics.
- Data Lake: Companies dealing with diverse, large-scale datasets, especially unstructured data, benefit from data lakes. Typical applications include IoT data storage, machine learning, and raw data aggregation.
- Data Lakehouse: Organizations looking for the flexibility of a data lake but needing high-performance structured queries should consider the lakehouse model. It’s useful for companies leveraging advanced analytics and real-time applications, such as personalized recommendation engines or AI model training.
Examples of GCP, AWS, Azure, Databricks, and Snowflake
Each cloud provider and data platform offers its take on these storage architectures:
- Google Cloud Platform (GCP): GCP offers BigQuery as a data warehouse solution, while Google Cloud Storage serves as its data lake offering. BigLake, introduced more recently, represents its lakehouse architecture, combining features of both.
- Amazon Web Services (AWS): AWS’s data warehouse solution is Amazon Redshift, while Amazon S3 acts as the backbone of its data lake services. AWS also now offers Amazon Redshift Spectrum to query S3 data from Redshift, mimicking a lakehouse setup.
- Microsoft Azure: Azure’s data warehouse solution is Azure Synapse Analytics, while Azure Data Lake Storage is designed for large-scale unstructured data. Azure Synapse attempts to integrate the lakehouse model by blending these two.
- Databricks: A major player in data lakehouse architecture, Databricks offers a unified platform for big data and AI through Delta Lake, a layer on top of data lakes that enables ACID transactions and high-performance analytics, bringing warehouse capabilities to a lake.
- Snowflake: Although originally a cloud data warehouse, Snowflake has evolved to support semi-structured and unstructured data, offering lakehouse-like features while maintaining its reputation for high-performance querying.
Whats next in line for organisations?
Understanding the differences between data lakes, warehouses, and lakehouses is critical to making informed decisions about data architecture. While data warehouses excel in structured data analytics, data lakes offer flexibility for unstructured data. Lakehouses, meanwhile, merge the best of both worlds, supporting a variety of modern analytics needs. Depending on your organization’s data strategy and technological requirements, platforms like GCP, AWS, Azure, Databricks, and Snowflake provide robust solutions tailored to fit each architecture.
To navigate the complexities of modern data architectures, from data lakes to warehouses and lakehouses, Polar Packet can help orchestrate tailored solutions for your business. Our expertise in cloud platforms like AWS, GCP, Azure, Databricks, and Snowflake ensures you’ll implement the most efficient and scalable data strategy, optimizing both performance and flexibility. Let Polar Packet guide your journey to harness the full power of your data.